





















En el mundo actual, que se digitaliza rápidamente, la importancia de la seguridad de los datos se ha vuelto primordial. Con la creciente cantidad de información sensible que se comparte y almacena en línea, proteger la información de ciberataques, fugas de información, y robos se ha convertido en una prioridad para empresas de todos los tamaños. La prevención de pérdida de datos (DLP) es una parte crítica de la plataforma de seguridad Netskope Intelligent Security Service Edge (SSE), que proporciona la mejor seguridad de datos de su clase a nuestros clientes.
Las imágenes suelen contener gran cantidad de datos valiosos y sensibles. Los documentos financieros, la identificación personal y las comunicaciones comerciales confidenciales suelen incluir imágenes que requieren la máxima seguridad. En Netskope, hemos desarrollado clasificadores de visión artificial basados en aprendizaje profundo de última generación que pueden analizar imágenes e identificar información sensible en una amplia variedad de categorías, como pasaportes, permisos/licencias de conducir, tarjetas de crédito y capturas de pantalla. Hemos obtenido cuatro patentes estadounidenses por nuestro enfoque innovador de la seguridad de los datos. En este artículo de blog, destacamos las recientes mejoras de nuestros clasificadores de imágenes que han dado como resultado una mayor precisión y una mejor experiencia del cliente.
Actualización de la arquitectura de las CNN
En el corazón de nuestros modelos de clasificación de imágenes se encuentran las redes neuronales convolucionales (CNN). Estos potentes algoritmos de aprendizaje profundo están diseñados específicamente para tareas de reconocimiento y clasificación de imágenes. Mediante el empleo de una técnica conocida como aprendizaje por transferencia, aprovechamos las CNN preexistentes que han sido entrenadas en conjuntos de datos a gran escala y las afinamos utilizando un conjunto de datos más pequeño de imágenes etiquetadas que contienen información sensible. Como resultado, nuestros clasificadores son capaces de identificar rápidamente los patrones únicos asociados a la información sensible, con una gran precisión y un tiempo de entrenamiento reducido.
La selección de modelos CNN pre-entrenados plantea varios problemas prácticos. Dado que nuestra plataforma SSE utiliza nuestros clasificadores para escanear millones de archivos de clientes diariamente, es crucial mantener los falsos positivos lo más bajo posible para evitar abrumar a los clientes con alertas espurias. Al mismo tiempo, dado que los verdaderos positivos indican una fuga de datos grave, mantener una tasa alta de verdaderos positivos es igualmente importante. Un reto adicional consiste en crear clasificadores lo suficientemente complejos como para cumplir nuestros objetivos de precisión, pero lo suficientemente compactos como para satisfacer nuestros estrictos requisitos de latencia, ya que se ejecutan en tiempo real en la plataforma SSE. Por ello, sólo consideramos arquitecturas de modelos de CNN pre-entrenados con menos de 10 millones de parámetros.
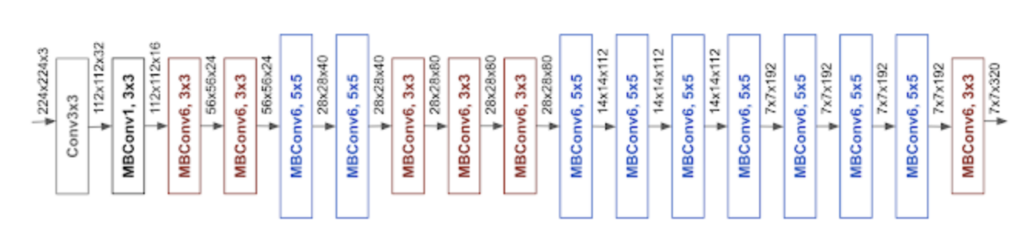
En nuestra última actualización del modelo, pasamos a la arquitectura pre-entrenada EfficientNet de CNN (modelada en la figura anterior). Esto supuso un aumento del 80% en el número de parámetros del modelo. El uso de un modelo pre-entrenado más grande supuso un modesto aumento de la latencia, pero dio lugar a un aumento significativo de la precisión en el mundo real.
Entrenamiento con datos reales de la nube
Para minimizar los falsos positivos, es importante que nuestros clasificadores de imágenes estén expuestos a una amplia variedad de muestras negativas realistas. Para conseguirlo, hemos obtenido decenas de miles de imágenes reales de nubes a partir de nuestros propios datos corporativos. Este enfoque nos permite recopilar un número considerable de imágenes de entrenamiento auténticas, al tiempo que mantenemos nuestro compromiso con la privacidad del cliente. Estas imágenes se etiquetaron a mano, y la mayoría de ellas eran ejemplos negativos o capturas de pantalla típicas de los datos de la nube del mundo real.
Además de estos ejemplos negativos aleatorios, también hemos incorporado varios miles de muestras adversarias cuidadosamente seleccionadas para reforzar la resiliencia de nuestros clasificadores frente a falsos positivos. Un tipo interesante de muestras adversarias son las etiquetas de productos electrónicos. Debido a sus fuentes en negrita y a su colorido de alto contraste, pueden confundirse con documentos sensibles. Al entrenar a nuestros clasificadores con estos ejemplos adversarios, podemos evitar eficazmente este tipo de clasificaciones erróneas en el entorno de producción.

Aumento de datos personalizado
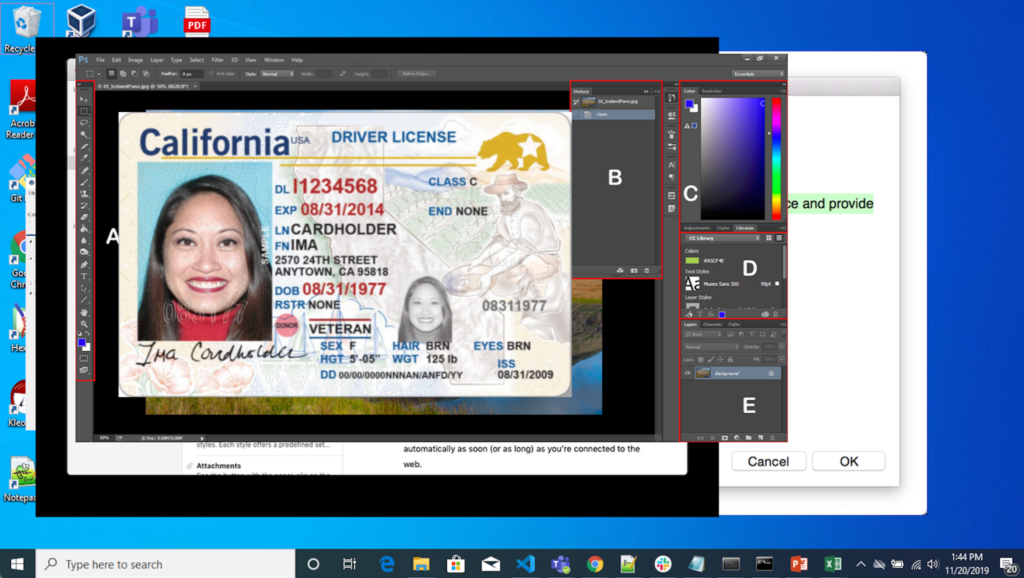
Además de obtener datos reales de la nube, empleamos un conjunto completo de técnicas de aumento de datos diseñadas específicamente para aplicaciones de visión artificial, como la rotación y el recorte. o que diferencia nuestro enfoque es la personalización de estos aumentos para garantizar la máxima fidelidad con los datos de imágenes que se encuentran en entornos reales en la nube. Un ejemplo es nuestro aumento personalizado que integra a la perfección documentos en fondos realistas, como un permiso/licencia de conducir pegado en una captura de pantalla. Esto permite que nuestros clasificadores se entrenen con documentos en una amplia gama de entornos, lo que aumenta significativamente su versatilidad y rendimiento con datos del mundo real.
Resumen
En nuestro afán por desarrollar soluciones de seguridad de IA de vanguardia, nos esforzamos continuamente por perfeccionar nuestras metodologías y fuentes de datos para construir modelos de seguridad de datos potentes y adaptables, capaces de salvaguardar el panorama digital en constante evolución.
Para obtener más información sobre cómo Netskope ayuda a los clientes a proteger sus datos sensibles en todas partes a nivel corporativo, visite prevención de pérdida de datos (DLP) de Netskope. Y para mantenerse al día con lo que nuestro equipo de AI Labs está escribiendo, por favor visite nuestra página de blog de AI Labs aquí.

